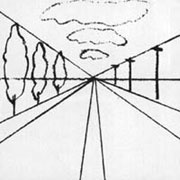
If true realism is the goal, there must be knowledge of perspective, which is the use of spatial elements to indicate depth and distance.
There are several types, but linear perspective, the most commonly used, is a good place to begin when designing a landscape. In linear perspective,
parallel lines converge to a vanishing point as they recede into the distance. In real life lines and planes that are parallel can never meet. They go on, side by side, forever.
In nature, apart from the world that humans have created, very few things are parallel. A river curves, a rocky coastline is erratic, and a forest is not an orchard. Yet there are implied parallel lines, as the two sides of a river meander together, and as the forest canopy maintains a uniform height above ground. Lines that are parallel to the ground and horizon help define the scale, or relative size, of objects.
The front and back of our sweaters are different, but must still work together as a single design, with side seams matching. The two sides must also be complete and striking on their own, since they will be viewed separately when finished. To achieve both of these objectives, we design them together as a horizontal view.
Both front and back share a common vanishing point.
Using angular or oblique perspective which has
two vanishing points.
There are many things to consider when you begin to compose the scene. What object or part of the scene deserves the greatest emphasis? This is the subject. Is the subject at our eye level, above us, or below us? Is the subject very
distant or very close? Is there more than one subject?
First you must choose a horizon line, the apparent meeting of earth and sky. A high horizon line will focus attention on objects placed in the foreground of the landscape since the area below the horizon will be larger than the area above it.
Because objects near the horizon line are more distant, they will appear to be smaller than foreground objects, and will show less detail than objects in the foreground.
As colors recede into the distance, they become lighter
in tone or color. This is known as aerial perspective.
So far, we have not mentioned a simple and obvious tool for creating depth, but which has been used in most of our designs. It is generally the first tool children use when they take interest in creating more realistic drawings: The placement of one object in front of or behind another, with the more distant object being partially obscured by the nearer one.